Teknologi - Core 2 Duo

Højere IPC – Flere instruktioner på samme tid
Med Core 2 har Intel valgt et design, der i langt højere grad end før fokuserer på en høj IPC ( Instructions Per clock Cycle). Groft sagt betyder det at man kan skubbe flere data igennem chippen per clockpuls. Der er flere grunde til at ønske en højere IPC, for det har en række klare fordele at være mindre afhængig af clockfrekvensen.
Dels stiller det mindre krav til hvor høje ”trin” der skal være imellem de clockfrekvenser man tilbyder. Et spring i clockfrekvens på eksempelvis 200Mhz kan sagtens forsvares fordi ydelsesforskellen er til at øje på. Dette betyder dels noget for slutbrugerne, men på det professionelle marked kan dette være rigtig fornuftigt fordi man få kunderne til løbende at opgradere til nyeste processorer fordi de kan mærke en reel forbedring i ydelsen. AMD har med stor succes gjort dette med Opteron-processoren, som på 2½ år er gået fra max 2GHz clockfrekvens til max 2.8GHz for hurtigste model. Ikke ligefrem et kvantespring, men trinene har været store nok til at folk har fundet det rimeligt at opgradere.
En anden fordel ved at være mindre afhængig af clockfrekvensen finder man i den anden ende af skalaen. Intel fik med Pentium M processoren vist at SpeedStep – hvor man dynamisk ændrer clockfrekvensen og processorspændingen efter behovet for regnekraft – havde enormt potentiale. AMD tog dette op med Cool’n’Quiet i deres K8 processorer og for begge arkitekturer gjaldt det at man selv ved lav clockfrekvens havde en fair ydelse – ene og alene fordi IPC’en var høj.
Dette er endnu en grund til at den høje IPC bør være vinder, men hvordan har Intel så grebet sagen an? Dels har man valgt en noget reduceret pipeline, som er på 14 stages. En kort pipeline er dog i så selv ikke alene nok til at give mere effektivitet, så Intel har tilført Wide Dynamic Execution. ”Almindelig” Dynamic Execution handler om at snyde processoren til at se en række instruktioner som én stor instruktion og derfor tage disse samlet og i rækkefølge. Grunden til at Dynamic Execution nu er blevet ”Wide” er at Intel i Core 2 arkitekturen har tilføjet en ny decoder og execution unit, så processoren nu kan håndtere fire x86 instruktioner samtidigt. Både Intel’s tidligere og AMD’s nuværende processorer kan maksimalt køre 3 x86 instruktioner samtidigt. Man får altså ikke bare en kortere pipeline, men også en bredere pipeline, som yderligere hæver IPC’en.

Mere cache
Dertil har man øget mængden af L1 cache i forhold til Pentium 4. Core 2 processorerne har fået 64KB L1 cache, hvilket er fordelt ligeligt imellem data og instruktion. Dette er langt mere L1 cache end i Pentium 4 arkitekturen, der grundlæggende havde 8KB L1 cache til data og 12KB til instruktion. Da Intel skiftede fra Northwood til Prescott blev mængden af cache til data fordoblet fra 8KB til 16KB, men Core processorerne har altså mere end det dobbelte.
Du kan i dag finde Core 2 processorer med alt fra 512kb op til 6MB L2 cache afhængigt af model, men da der er tale om dual-core processorer vil L2 cache’en blive delt imellem de to CPU kerner. Dette sker fordi Intel har implementeret deres Smart Cache. Med den kan man dynamisk allokere cache-mængde til hver enkelt processorkerne. Kører man således en applikation, som kun kan udnytte den ene processor vil denne ene processor få den fulde mængde cache til sin rådighed.
Dette er på papiret smart, men som man hurtigt vil se så er denne feature meget lidt værd i praksis – en dual-core processor vil nemlig næsten altid bruge begge cores i større eller mindre grad fordi operativsystemet (og flere andre underliggende applikationer) bruger CPU-tid. Derfor har Intel med deres Smart Cache implementeret en Crossbar funktion, som dynamisk deler cache-mængden imellem de to processorkerner.
Udover denne glimrende funktion har Intel gjort en del for at pre-fetche data til cache’en endnu bedre end før. Dels er selve pre-fetch algoritmen optimeret, men en ny feature går ud på at hvis processor-kerne 1 skal bruge data som ligger i cache’en hos processor-kerne 2, så kan processor-kerne 1 tage den databid direkte. Tidligere ville man i dette tilfælde skulle have data’en ud af processor-kerne 2’s cache og ind i processoren igen, hvilket gav høj latency.

Men ikke kun data til cache pre-fetches bedre. Intel Smart Memory Access dækker over en generelt forbedret pre-fetch del i processoren. For x86 kode gælder det normalt at cirka 20 procent af instruktionerne kræver adgang til hukommelsen og her er netop prefetch-delen vigtig. Core 2 processorerne har her seks uafhængige pre-fetch enheder, der alle har en forbedret algoritme til at ramme præcis den data som processoren skal bruge. Dertil har Smart Memory Access fået en ny feature, som tillader at en ny instruktion kan startes selvom den er afhængig af resultatet af en tidligere instruktion – dette minimerer out-of-order, hvor en instruktion ellers må bremses fordi der ventes på data.
EM64T, SSE, osv.
En anden stor forbedring i Core 2 arkitekturen er at 64-bit understøttelsen er på plads i alle processorer. Intel benytter fortsat sin egen EM64T (Enhanced Memory 64 Technology) til at varetage 64-bit delen, men som Intel’s markedsføring tegner sig vil det primært blive på server-området at man vil slå på EM64T. Dette giver såmænd også ganske god mening, da der mangler langt bedre softwareunderstøttelse for at 64-bit kan blive en succes på desktoppen.
SSE instruktionssættet vil også blive forbedret i Core 2 arkitekturen. Således vil alle 128-bit SSE instruktioner nu kunne beregnes på en enkelt clockcyklus – tidligere krævede dette to af slagsen. Da SSE instruktioner oftest benyttes ved multimedia kalder Intel denne nye feature for Intel Advanced Digital Media Boost.
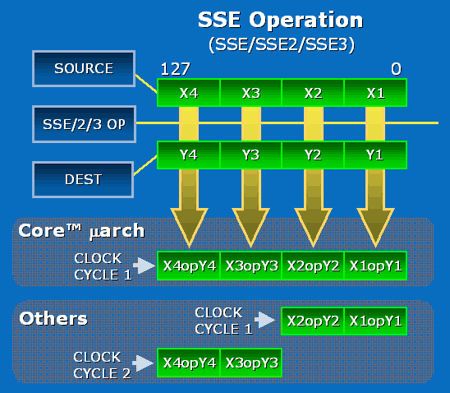
SSE4 finder også vej til Core 2 – Pentium 4 processorerne havde SSE, SSE2 og SSE3, men nu kommer der yderligere 8 instruktioner, som samles under SSE4 betegnelsen. Disse var tidligere tiltænkt Tejas-processoren, som Intel droppede til fordel for netop Core arkitekturen. Derfor blev disse også tidligere kaldt TNI (Tejas New Instructions), men er nu en del af SSE3.
NX (No eXecutable) Bit vil uændret finde vej til Core 2 og dermed tilbyde samme beskyttelse overfor skadelig kode, som Intel fik introduceret i sine seneste Pentium processorer. Også Intel’s VT (Virtualization Technology) vil være standard i Core 2 processorerne, der igen overtager disse teknologier uforandrede fra de seneste Pentium-processorer.
Lavere strømforbrug
Strømforbruget har været en særdeles vigtig faktor i udviklingen af Core 2 arkitekturen og det har betydet at Intel yderligere har arbejdet på at sænke dette. Dels benytter man deres Enhanced SpeedStep, som tilpasser processorens clockfrekvens – og dertil også processorspændingen – til behovet for regnekraft.
Yderligere har man forbedret muligheden for at kunne lukke ned for dele af processoren når disse ikke skal bruges. Som en del af Intel’s Smart Cache har Intel implementeret at processoren kan lukke sin cache helt ned – simpelthen ved at flushe data’en – og synke til et endnu lavere energiniveau. Når der igen er brug for databehandling, som kræver cache, så startes den dynamisk op igen og processoren går tilbage i sit normale energiniveau. Denne feature så man allerede på Yonah-processoren, men nu finder den vej til Core 2 også.
Ydermere er Core 2 processoren delt ind i mange mindre områder end eksempelvis Pentium 4 var. Disse mindre dele kan derfor oftere lukkes ned, hvis der ikke er brug for dem og det giver igen et lavere effektforbrug.
En pudsig detalje omkring dette er at Intel dermed har fået svært ved at angive processorens temperatur. Undervejs i udviklingen fandt man simpelthen ud af at processortemperaturen kunne variere meget imellem de forskellige områder, hvorfor en almindelig løsning med en enkelt temperaturdiode ikke altid ville give et præcist billede af processorens temperatur. Derfor har man i Core 2 processorerne placeret flere dioder rundt i processoren og når man checker temperaturen på sin Core 2 processor er det faktisk et gennemsnit af disse forskellige værdier, som man aflæser.









