
Test: Intel Core 2 Duo E6850
CPU, Intel d. 27. oktober. 2007, skrevet af Stensgaard 13 Kommentarer. Vist: 31638 gange.
Korrekturlæser:
Billed behandling:
Oversættelse:
Pristjek på http://www.pricerunner.dk
Produkt udlånt af: Intel
DK distributør: InterData
Billed behandling:
Oversættelse:
Pristjek på http://www.pricerunner.dk
Produkt udlånt af: Intel
DK distributør: InterData
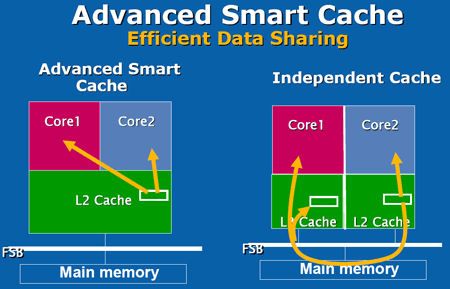
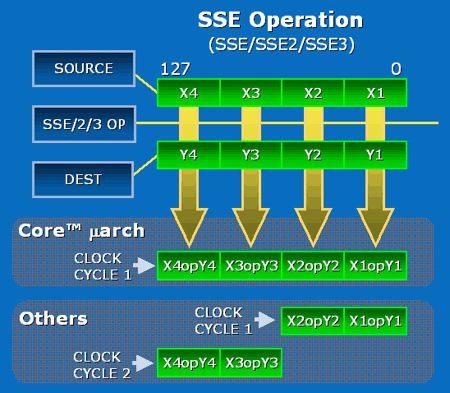
#1
fint i bruger tid på det med ram,men i skulle bruge lidt mere tid på det ;)
ram ydelse på et P35 chip
http://www.xbitlabs.com/articl...
jeg er ikke vendt tilbage 😀
ram ydelse på et P35 chip
http://www.xbitlabs.com/articl...
jeg er ikke vendt tilbage 😀
#2

#1 Ja, den artikel har du linket til før, og jeg har også læst den. Der står, at 1T Command Rate kun virker ved 5:6 og 5:8, og at det alligevel kun giver 0,5% ekstra ydelse i forhold til 2T.
Synes du, det er vigtigt at få det med?
Synes du, det er vigtigt at få det med?
#3

Hvorfor hedder den x6850 i 3dmark?

#1 troede du var færdig med at være herinde?
lækker test bortset fra som #3 siger; hvorfor hedder den X6850 i benchmark testne?
lækker test bortset fra som #3 siger; hvorfor hedder den X6850 i benchmark testne?
#5

Hvordan yder 6850'eren i forhold til Q6600'eren? da de har samme pris vil jeg godt vide vilken der var bedste at købe.
#6

-> #3 + #4
Måske fordi Core 2 Duo hedder et eller andet med 'X' foran? Ved det ikke, men tror det er derfor...
Måske fordi Core 2 Duo hedder et eller andet med 'X' foran? Ved det ikke, men tror det er derfor...
#7

# 3+4
Fordi det er en engineering sample....yes yes.....vi kender nogen der kender nogen 😀
Fordi det er en engineering sample....yes yes.....vi kender nogen der kender nogen 😀
#8
#3 + #4: Den er lige smuttet, beklager 😳 . Det skyldes, at vi først fik at vide, at det var en Core 2 Extreme X6850, som var på vej. Vi fandt så siden hen ud af, at det "bare" var en E6850. Som man kan se på billedet af CPU'en, er det en ES, så man kan ikke umiddelbart se, hvad den ellers er. Og diagrammerne er lavet, før vi fandt ud af fejlen.
#5 E6850 yder umiddelbart bedst, men Q6600 er bedre til seriøs multitasking.
#5 E6850 yder umiddelbart bedst, men Q6600 er bedre til seriøs multitasking.
#9

->#5
Som Stensgaard siger, er en hurtig dualcore klart at foretrække frem for en mindre hurtig quadcore når man spiller og sådan nogle ting. For spil udnytter endnu ikke quadcore.
Men kører man flere programmer ad gangen, er en quadcore fed at have: http://hwt.dk/literaturedetail...
Som Stensgaard siger, er en hurtig dualcore klart at foretrække frem for en mindre hurtig quadcore når man spiller og sådan nogle ting. For spil udnytter endnu ikke quadcore.
Men kører man flere programmer ad gangen, er en quadcore fed at have: http://hwt.dk/literaturedetail...
#10
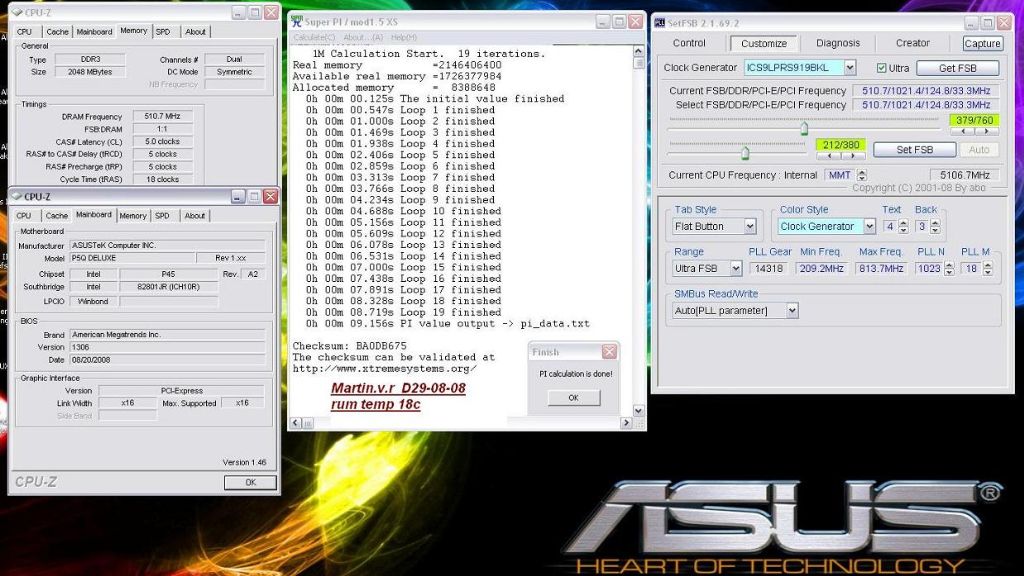
ok jeg er en lille noob til OC :'-(
men ser i testen at der køres på et bundkort som mit abit ip35 pro ( jeg har bare ip35) og en e6300 cpu men her køre den cpu 1333 fsp hved at sætte den til 333 mhz i bios.
kan jeg uden problemr gøre det samme. jeg har en god luft køler på? eller skal jeg ændre andet, er der noget der kan gå galt?
( er lidt presset af den nye crysis demo 😉 )
men ser i testen at der køres på et bundkort som mit abit ip35 pro ( jeg har bare ip35) og en e6300 cpu men her køre den cpu 1333 fsp hved at sætte den til 333 mhz i bios.
kan jeg uden problemr gøre det samme. jeg har en god luft køler på? eller skal jeg ændre andet, er der noget der kan gå galt?
( er lidt presset af den nye crysis demo 😉 )
#11
#10 Du burde uden problemer kunne sætte FSB op fra 266 til 333. Og så længe du ikke piller ved spændinger/Vcore, er der ikke noget, der går helt galt.
#12

nogen der gider hjælpe mig med at overclocke min intel duo 2.4 6600
har ikke noget program til det !
har ikke noget program til det !
#13

#10 + #12 I må lige oprettet en tråd, til det 🙂 Så vil vi lige gå tilbage til topic her 😉
Jeg er uenig med jer drenge..... jeg ville klart vælge en Q6600 frem for en E6850. Hvis du har kølingen, kan en quad jo også godt rende 3,8 - 4 ghz 😉
Mange af de nye spil. og programmer. understøtter jo 4 kerner, eller mere 😉 Som f.eks. Crysis.
Selv hvis de "kun" kan udnytte de to kerner, så kan quad core'en dedikere to kerner til spillet, og to til baggrundsressourcer.
Jeg er uenig med jer drenge..... jeg ville klart vælge en Q6600 frem for en E6850. Hvis du har kølingen, kan en quad jo også godt rende 3,8 - 4 ghz 😉
Mange af de nye spil. og programmer. understøtter jo 4 kerner, eller mere 😉 Som f.eks. Crysis.
Selv hvis de "kun" kan udnytte de to kerner, så kan quad core'en dedikere to kerner til spillet, og to til baggrundsressourcer.