
Test: Intel QX9650 Yorkfield
CPU, Intel d. 22. december. 2007, skrevet af Polarfar 29 Kommentarer. Vist: 17214 gange.
Korrekturlæser:
Billed behandling:
Oversættelse:
Pristjek på http://www.pricerunner.dk
Produkt udlånt af: Intel
DK distributør: Tech Data
Billed behandling:
Oversættelse:
Pristjek på http://www.pricerunner.dk
Produkt udlånt af: Intel
DK distributør: Tech Data


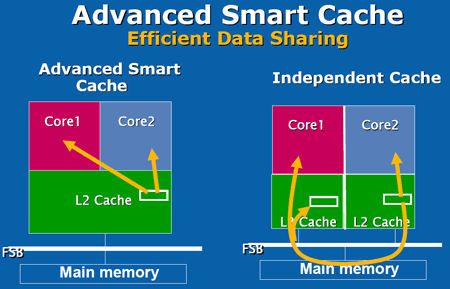
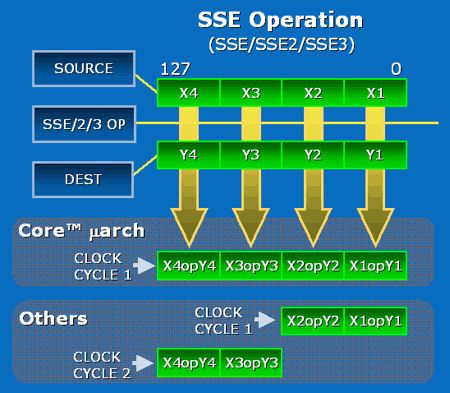
#1

Fin test.. Synes bare det er lidt fesent fra intels side at smide ne 45 nm ud der ikke yder meget bedre end den gamle topmodel ud over lige på oc området..
og måske også strøm forbrug ? Er det ikke noget i for mulighed for at teste?
og måske også strøm forbrug ? Er det ikke noget i for mulighed for at teste?
#2

#1 jeg vil prøve med en måling af strømforbruget på den 9770'er jeg har fået i julegave....h*st....jeg mener... til test 🙂 så det er med i overvejelserne.
#3

Polarfar > En fsb på 470 Mhz er da også ganske respektabelt for en quadcore, har du prøvet den på andre bundkort endnu? Glæder mig til at høre om dine strømmålinger.
Jeg kan se at Sioux har fået gang i en 9650 også, og efter hans resultater og hvad jeg har set hidtil er de nye 45 nm chips efter alt at dømme noget mildere ved os med max ~200W kompressorkøling.
Jeg kan se at Sioux har fået gang i en 9650 også, og efter hans resultater og hvad jeg har set hidtil er de nye 45 nm chips efter alt at dømme noget mildere ved os med max ~200W kompressorkøling.
#4
Fin test Polarfar, Ahh tag så lidt at få smækket en test op af den QX9770 engang 😛 !
#5

jeg synes inde på toms at ha læst at en QX9650 lammertæver alle andre cpuer i FPS i alle spil den blev testet i.... reallife test må jo være spil og ikke syntetiske test
ellers fin lille test 😉
ellers fin lille test 😉
#6
#3
470 er bestemt i den gode ende, men det lader til at den bedre kan lide en højere multiplier. Jeg har ikke testet den med Vapo eller tøris, men en spand med isvand er jo altid ved hånden 🙂
470 er bestemt i den gode ende, men det lader til at den bedre kan lide en højere multiplier. Jeg har ikke testet den med Vapo eller tøris, men en spand med isvand er jo altid ved hånden 🙂
#7
#6 > Takker, så har jeg lidt at pejle efter 😉
#8

Sådan skulle det se ud, men ak....
Ahh man må ikke lyve Polarfar 😀, kassen ser sådan ud:

Den er dobbelt så stor som en normal kasse og der er også kommet en helt ny box køler med :yes:
Hey Lars... long time no see 🙂
Ja de normale quad cores tvinger ret hurtig en 200W kompressor i gulvet, men de nye 45nm bliver ikke varmere end en normal dual core. Det betyder at man godt kan nå de 5GHz på en ~200W kompressor 😉
Ahh man må ikke lyve Polarfar 😀, kassen ser sådan ud:
Den er dobbelt så stor som en normal kasse og der er også kommet en helt ny box køler med :yes:
Hey Lars... long time no see 🙂
Ja de normale quad cores tvinger ret hurtig en 200W kompressor i gulvet, men de nye 45nm bliver ikke varmere end en normal dual core. Det betyder at man godt kan nå de 5GHz på en ~200W kompressor 😉
#9
#8 vi lyver altid som gale og håber ingen opdager det 😀
Jeg havde forhørt mig omkring kassen og den nye box-køler, men ingen kunne give et fyldestgørende svar, så jeg regnede med at det var som den forrige. Sådan går det jo nogengange.
Jeg havde forhørt mig omkring kassen og den nye box-køler, men ingen kunne give et fyldestgørende svar, så jeg regnede med at det var som den forrige. Sådan går det jo nogengange.
#10

når ja er det ikke den bling bling køler, intels nye? 😀
#11
#10 Det er vist noget med at den grimme runde stock køler har fået et par blå LED's og blevet lidt større - altså ingen heatpipes - på køler området kunne de lære noget af AMD's heatpipe stock køler
#2 Lyder godt - Håber at noget strømforbrugs test i fremtiden ;)
#2 Lyder godt - Håber at noget strømforbrugs test i fremtiden ;)
#12

#3 Min Q6600 B3 render 480 mhz fsb, men ja de 470 er også respektabelt 🙂
#8 I følge diverste programmer smidder min 210 watt @ 3,6 ghz med 1,5 vcore 😐
#8 I følge diverste programmer smidder min 210 watt @ 3,6 ghz med 1,5 vcore 😐
#13

Vi har tidl. skrevet om Intels nye stockkøler, som følger med til QX9650: http://hwt.dk/newsdetails.aspx...
#14
#9
Haha 🤣..... Jeg udfordre dig til duel! 😎

Køling: Intels gamle box køler 😛
Haha 🤣..... Jeg udfordre dig til duel! 😎
Køling: Intels gamle box køler 😛
#15
Hehe, dueller. Jeg elsker dueller, eller bare et lille battle for den sags skyld.
Pederrs > Ja det er et stykke tid siden, men nu er 45 nm chips'ene jo kommet, og det er juleferie, dvs. tid til at lege lidt igen.
#12 > Hvilket bundkort er det på? Mit P5B-Dlx kan jeg også godt få op på omkring 460 Mhz fsb stabilt med min QX6700, men så kan jeg ikke få mine Corsair 8888 ram til at køre optimal hastighed. Mht. volt så tror jeg det passer meget godt. Ca 3.6 Ghz ved 1.475V i bios er grænsen for hvad mit Mach II GT kan klare til full load på alle 4 kerner med min QX6700.
Nå, jeg må vel hellere få smidt den QX9650ES i Mach'en, nu har den ligget på mit bord i en lille uges tid. 🙂
Pederrs > Ja det er et stykke tid siden, men nu er 45 nm chips'ene jo kommet, og det er juleferie, dvs. tid til at lege lidt igen.
#12 > Hvilket bundkort er det på? Mit P5B-Dlx kan jeg også godt få op på omkring 460 Mhz fsb stabilt med min QX6700, men så kan jeg ikke få mine Corsair 8888 ram til at køre optimal hastighed. Mht. volt så tror jeg det passer meget godt. Ca 3.6 Ghz ved 1.475V i bios er grænsen for hvad mit Mach II GT kan klare til full load på alle 4 kerner med min QX6700.
Nå, jeg må vel hellere få smidt den QX9650ES i Mach'en, nu har den ligget på mit bord i en lille uges tid. 🙂
#16
#15 WB Lars 🙂 Long time no see.
MSI P35 Platinium ftw. ❤ Har set folk rende 560 mhz fsb på det mobo med en dual core, og det koster 1100 kr 😎 ABIT IP35 PRO kan SLET ikke være med 😛
Og jeg har forøvrigt "bare" vandkøling på 🙂
Men kom så med de resultater Lars ! 😀
MSI P35 Platinium ftw. ❤ Har set folk rende 560 mhz fsb på det mobo med en dual core, og det koster 1100 kr 😎 ABIT IP35 PRO kan SLET ikke være med 😛
Og jeg har forøvrigt "bare" vandkøling på 🙂
Men kom så med de resultater Lars ! 😀
#17
Hehe Claus så se hvilken FSB jeg har opnået på mit P5K Premium (og det er med en quad core 😛):
http://valid.x86-secret.com/sh...
Abit IP35 Pro køre fint, når det ellers får den rette bios. Resultatet med QX9650'eren er lavet på Abit bundkortet.
#15
Hehe så må jeg vel hellere se at få smidt min kompressor på den, ellers bliver det vist lidt urimeligt 😀
http://valid.x86-secret.com/sh...
Abit IP35 Pro køre fint, når det ellers får den rette bios. Resultatet med QX9650'eren er lavet på Abit bundkortet.
#15
Hehe så må jeg vel hellere se at få smidt min kompressor på den, ellers bliver det vist lidt urimeligt 😀
#18

hi lars welcome back . nice test polar far 😉
#19
#17 Hvad er så den rette BIOS? Jeg har prøvet med to versioner hvor den ene var den der var på da jeg fik det, og så smed jeg den nyest på 😛
350 mhz fsb blev det til, og med Nosfer@tu's hjælp, blev det til slående og utrolige 355 mhz fsb 😐 Så nupper Emillos bundkortet, og smider en QX6700 på og rammer 486 mhz fsb 😐 :-S Og jeg er altså ikke en dårlig clocker, og jeg er slet ikke den eneste der har problemer med at oc Q6600 på IP35, men der er sgu nogen der kan.... Men er der egentligt nogen der har lavet et vellykket oc med IP35 PRO med en Q6600? Og ikke en QX?
EDIT: Pederrs -> Du tæller ikke 😛
350 mhz fsb blev det til, og med Nosfer@tu's hjælp, blev det til slående og utrolige 355 mhz fsb 😐 Så nupper Emillos bundkortet, og smider en QX6700 på og rammer 486 mhz fsb 😐 :-S Og jeg er altså ikke en dårlig clocker, og jeg er slet ikke den eneste der har problemer med at oc Q6600 på IP35, men der er sgu nogen der kan.... Men er der egentligt nogen der har lavet et vellykket oc med IP35 PRO med en Q6600? Og ikke en QX?
EDIT: Pederrs -> Du tæller ikke 😛
#20
Hey Lars.. WB - du oh stormester ud i monster-OC-tråde 🙂
Så skal vi da snart ha en "ska I ha en lille lars-test?" - tråd igen ikk?
w00t 😲
Så skal vi da snart ha en "ska I ha en lille lars-test?" - tråd igen ikk?
w00t 😲
#21
Hey guys, jo tak og jeg er tilbage i oc gamet. Har tilbragt en hyggelig aften med svigerfamilien så jeg regner med at starte op i morgen formiddag med at installere den nye cpu. Indtil videre bare i mit P5B-Dlx.
#16 > Jeg checker lige det bundkort, lyder vildt at MSI laver noget Abit ikke kan følge med, men det mått jo ske på et tidspunkt 😀
#17 > Mon ikke det er en meget god idé med kompressoren....Nice fsb 😉
#18 > Jo tak, jeg har godt nok efterhånden også savnet lidt hardware/oc snak i hverdagen.
#20 > Det skulle undre mig meget om ikke der dukker et eller andet op i løbet af i morgen, i alt fald senest i løbet af jule/nytårs ferien.
#16 > Jeg checker lige det bundkort, lyder vildt at MSI laver noget Abit ikke kan følge med, men det mått jo ske på et tidspunkt 😀
#17 > Mon ikke det er en meget god idé med kompressoren....Nice fsb 😉
#18 > Jo tak, jeg har godt nok efterhånden også savnet lidt hardware/oc snak i hverdagen.
#20 > Det skulle undre mig meget om ikke der dukker et eller andet op i løbet af i morgen, i alt fald senest i løbet af jule/nytårs ferien.
#22
savle savle - vi glæder os kan jeg vist godt sige på vegne af hele hwt.dk 🙂
nu er der en time til d.24!!!!!!!!!!!!
i cant sleep!!!!
😲
nu er der en time til d.24!!!!!!!!!!!!
i cant sleep!!!!
😲
#23
#22 > LOL, sov du nu bare, jeg sidder ved laptoppen og er ved at være træt, så det bliver først op ad dagen i morgen, og dine gaver får du vel først i morgen aften..... 😀
#24
#19
Nu kan det jo også være din Q6600 der ikke kan tage en højere FSB. Jeg bruger selv beta bios 16.B04 lige nu. Tjek den her tråd:
http://www.xtremesystems.org/f...
Nu kan det jo også være din Q6600 der ikke kan tage en højere FSB. Jeg bruger selv beta bios 16.B04 lige nu. Tjek den her tråd:
http://www.xtremesystems.org/f...
#25
Har kigget på en del af de sider der, men har sgu ikke liiiige læst hele tråden 😐 Jeg har jo så set en masse oc resultater, hvor langt største delen var på dual cores og dem der var med quads var sjovt nok G0'er, hvor min er en B3'er.... Så måske er det med B3 IP35 har probs?
Nå,.... men det er i hvert fald ikke et bundkort jeg ville købe....det kan godt være det er et super oc board, men man kan altså også risikerer, at lårtet ikke funker 😕
Nå,.... men det er i hvert fald ikke et bundkort jeg ville købe....det kan godt være det er et super oc board, men man kan altså også risikerer, at lårtet ikke funker 😕
#26
Nå jeg havde super travlt i julen, og to fødselsdage i familien er der også i julen, så jeg har først fået smækket svinet i nu. Har jo læst lidt reviews rundt omkring så jeg bootede direkte op i windows @ 4 Ghz http://valid.x86-secret.com/sh...
Nu skal der leges de næste par dage.... bare som et lille supplement til Polarfar's test naturligvis 😉
Nu skal der leges de næste par dage.... bare som et lille supplement til Polarfar's test naturligvis 😉
#27
#26
lol....ja det vil jo undre alle inklusive mig selv hvis du kan få den over mine 4.4GHz....
hvis du forstår sådan en lille een der 😀
- og godt nytår.
lol....ja det vil jo undre alle inklusive mig selv hvis du kan få den over mine 4.4GHz....
hvis du forstår sådan en lille een der 😀
- og godt nytår.
#28
#27 > LOL, sjovt nok om jeg ikke lige fik den en smule over de 4.4 Ghz.... 😀
#29

så kom en anden under 10sek også. Ikke noget som en lille OC test til at starte 1. januar på 🙂
Jeg skylder at sige at det IKKE er med en QX9650, men en anden QX model 😉